本文基于jdk1.8介绍LinkedHashMap。
LinkedHashMap
在上一篇文章Java集合框架之HashMap详解中, 我们介绍了Java集合框架的一个类HashMap。通过源码分析,我们了解了HashMap的存储结构和内部实现,如果还有不清楚的,那就再回顾一下,因为我们今天要介绍的LinkedHashMap是HashMap的子类,很多方法和属性都直接继承于HashMap。
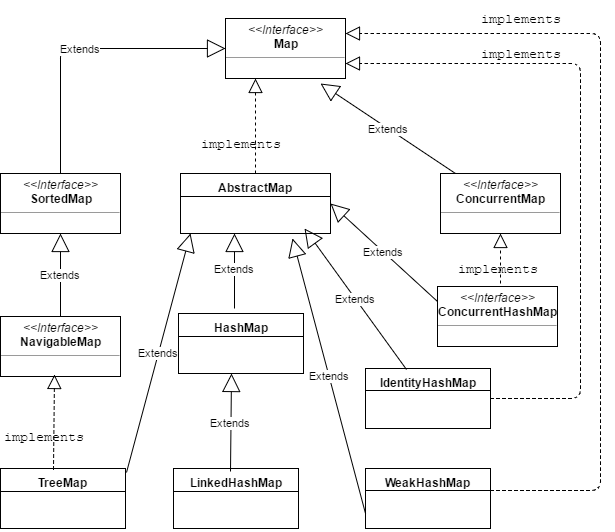
与HashMap异同
从上面的类图中我们可以看到,LinkedHashMap直接继承自HashMap,所以LinkedHashMap拥有HashMap的大部分特性,最多只允许一个key为null,可以有多个value为null。一些主要的方法和属性也直接继承自HashMap,并对其中某些方法进行了重写。LinkedHashMap与HashMap最大的不同在于LinkedHashMap保持了元素的有序性,即遍历LinkedHashMap的时候,得到的元素的顺序与添加元素的顺序是相同的,可以按照插入序 (insertion-order)或访问序 (access-order)来对哈希表中的元素进行遍历。
所谓插入顺序,就是
Entry被添加到Map中的顺序,更新一个Key关联的Value并不会对插入顺序造成影响,而访问顺序则是对所有Entry按照最近访问(least-recently)到最远访问(most-recently)进行排序,读写都会影响到访问顺序,但是对迭代器(entrySet(), keySet(), values())的访问不会影响到访问顺序。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
顺序存取原理
LinkedHashMap之所以能实现存取的顺序性,主要是他重新定义了 Entry<K,V> ,这个新的 Entry<K,V> 继承自HashMap.Node<K,V>,并做了新的扩展,下面我们结合源码来分析一下。
|
|
存取结构
由上面的代码我们可以看出,这个自定义的 Entry<K,V>比 HashMap.Node<K,V>多了两个属性,before和after。正是使用这两个关键的属性,在LinkedHashMap内部实现了一个双向链表。数据结构的知识大家再回忆一下(想不起来的可以去面壁了),双向链表就是每个节点除了存储数据本身之外,还保存着两个指针,在java里面就是指向对象的引用,一个是前驱节点,也就是他的前一个节点的引用,一个是后继节点,也就是他的后一个节点的引用。这样,就可以实现存储一个有序节点的数据结构了。(这里说明下,在jdk1.7中,使用的结构为环形双向链表)另外,继承自HashMap.Node<K,V>的Entry<K,V>自身还保留着用于维持单链表的next属性,因此LinkedHashMap的Entry节点具有三个指针域,next指针维护Hash桶中冲突key的链表,before和after维护双向链表。结构如下图所示:
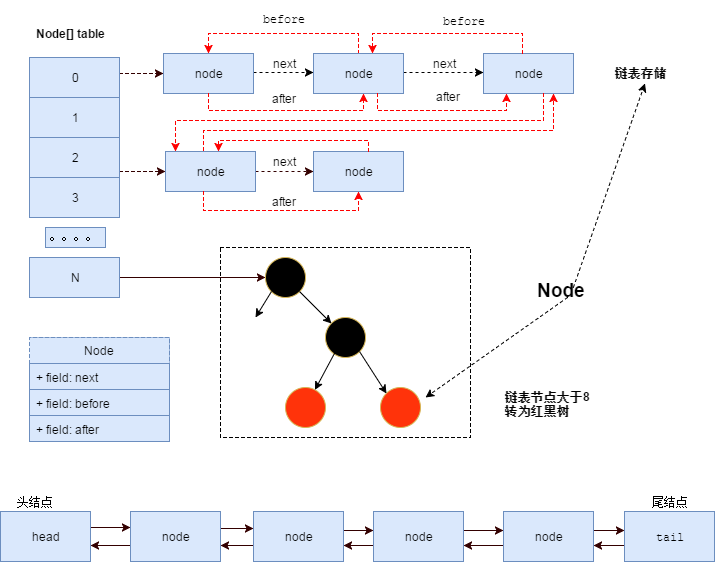
以上就是
LinkedHashMap的数据结构,但是光有数据机构显然无法完成有序的存取,下面我们继续来看一下,LinkedHashMap的存取过程。
存取过程
上面提到LinkedHashMap继承自HashMap,所以,LinkedHashMap的自身便拥有了HashMap全部的属性和方法。由代码我们也能看出,LinkedHashMap自身并没有实现put方法,而是直接使用其父类HashMap的put方法。不同的是,在创建Entry时,重写了父类的newNode(int hash, K key, V value, Node<K,V> e) {}方法,并实现了父类预留的回调方法,通过重写父类的方法和回调方法,LinkedHashMap扩展了HashMap,使其拥有了保持存取顺序性的能力。从这点我们也可以看出,java的开发团队将这一功能实现的比较优雅,其中的思想值得我们在开发中借鉴和学习,这也是我们阅读java源码的意义所在。
LinkedHashMap的put过程和HashMap大致相同,包括计算hash值、计算table数组索引、判断数组是否为空等步骤,不同的是创建节点的过程。从上面的代码中我们可以看出,重写的这个newNode方法代码比较简洁,首先实例化一个双链表结构的Entry<K,V> p,这里会首先调用其父类 HashMap.Node的构造方法,维护着一个单链表的结构。实例化结束后,会调用一个linkNodeLast的私有方法,这个方法完成了将新的元素添加至双向链表的尾部的功能。我们知道,在HashMap中,如果单链表超过一定的长度,就会被转换为红黑树,那么在LinkedHashMap中也是同样的逻辑,于是就有了下面的代码。
|
|
这两个也是被重写的方法,当存储结构为红黑树的时候,调用newTreeNode方法创建红黑树节点。当需要将链表转换为红黑树结构时,调用replacementTreeNode方法将双向链表中的TreeNode替换为新的链表节点。
由以上分析过程可以得出结论,在 LinkedHashMap 中,所有的 Entry 都被串联在一个双向链表中。每次在新建一个节点时都会将新建的节点链接到双向链表的末尾。这样从双向链表的尾部向头部遍历就可以保证插入顺序了,头部节点是最早添加的节点,而尾部节点则是最近添加的节点。上面我们还提到,LinkedHashMap可以实现插入的顺序和访问的顺序,那么访问的顺序是怎样实现的呢?下面我们来看一下。
我们通过观察LinkedHashMap的构造函数可以发现有这样一个字段,accessOrder,他的初始值为false。这个字段的意思是是否使用访问序,所以LinkedHashMap的默认顺序为插入顺序。上文我们提到了在HashMap类中预留了几个回调方法,这几个方法在HashMap中并没有实现,而在LinkedHashMap中这几个方法都有了具体的实现,这些方法就是为了实现访问序,下面我们结合代码来看一下。
在插入节点、删除节点和访问节点后会调用相应的回调函数。可以看到,在 afterNodeAccess 方法中,如果该LinkedHashMap是访问序,且当前访问的节点不是尾部节点,则该节点会被置为双链表的尾节点。即,在访问序下,最近访问的节点会是尾节点,头节点则是最远访问的节点。
遍历
|
|
可以看到,在遍历所有节点时是通过节点的 after 引用进行的。这样,可以从双链表的头部遍历到到双链表的尾部。
总结
关于LinkedHashMap,我们就介绍到这里,当然,在这里只列出了部门比较重要的方法,还有很多的方法我们没有分析。如果有兴趣,大家可以对照着jdk1.7和jdk1.8的源码进行分析,会发现两者的实现方式还是有很大区别的。
参考
http://blog.jrwang.me/2016/java-collections-linkedhashmap/
http://www.cnblogs.com/chenpi/p/5294077.html
http://blog.csdn.net/qq_24692041/article/details/64904806