本文基于jdk1.8介绍Set接口下的常用实现类。
java 集合框架
在前两篇文章中, 我们介绍了Java集合框架下List接口下的ArrayList和LinkedList两个实现类,今天我们来看一下Set接口下的几个实现类HashSet、LinkedHashSet和TreeSet。下面还是先来看一下Collection接口的类图:
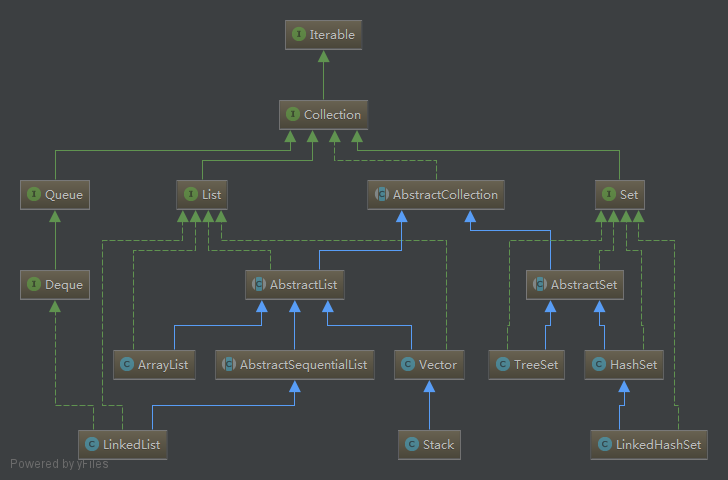
由类图我们可以看到,set接口继承自Collection接口且有四个实现类,分别为AbstractSet、HashSet、LinkedHashSet和TreeSet,其中AbstractSet为抽象类,继承自AbstractCollection,实现了最基本的Collection骨架。下面我们分别来看一下其余三个实现类的实现原理。
HashSet
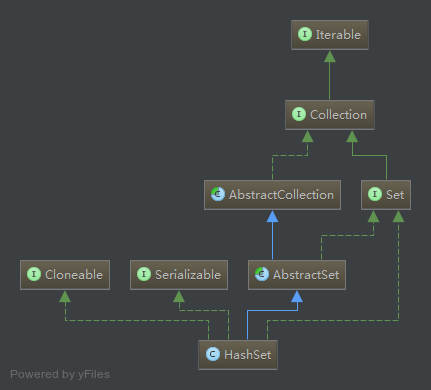
对于HashSet而言,它是基于HashMap实现的,可以看作是对HashMap的封装,HashSet底层使用HashMap来保存所有元素,因此HashSet的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成, 如果看过了HashMap的源码之后,再来看HashSet会比较好理解一些,如果对HashMap的原理不熟悉的话,可以先回顾一下我们前几天对HashMap分析的博文Java集合框架之HashMap详解。下面我们结合源码来具体分析一下HashSet的具体实现。
成员变量
首先看一下两个成员变量
通过这两个成员变量我们可以看到,在HashSet的内部维护着一个HashMap类型的变量map,这个map就是用来存储元素的容器。那我们知道,HashMap存储的是key-value形式的键值对,而set是一个单值对象,这要怎么存储呢?那就要看第二个成员变量PRESENT了,PRESENT是一个Object对象,这个对象就是充当键值对的值的,也就是说,我们只会把需要存储的元素当作map的key,而对应的value则默认为这个Object对象,这就是HashSet内部实现存储元素的数据结构。所以由HashMap的特性我们可以知道,HashSet存储的元素是无序的,元素不是不可重复的并且可以为null,基于这个元素不允许重复的特性,HashSet经常被用来做元素的去重。
构造方法
下面我们看一下HashSet提供的构造方法。
|
|
HashSet一共提供了5个构造方法,由构造方法也可以看到,底层是用了HashMap的数据结构实现,构造方法也跟HashMap比较类似,这里重点要说一下HashSet(int initialCapacity, float loadFactor, boolean dummy)这个构造方法,这个构造方法是不对外部公开的,其实放在这里实现是为了给LinkedHashSet使用,下文我们会讲到这一点。
存取实现
添加元素
由于底层使用了HashMap作存储结构,这里直接调用了HashMap的put方法插入元素,元素被作为key插入的map中,而value则是使用的默认值Object对象。
遍历HashSet支持两种遍历方式,Iterator方式,foreach方式,不支持随机访问方式遍历。
|
|
特性总结
1、由于底层基于HashMap实现,内部使用基于哈希表的数组+链表方式存储,所以不保证元素的存取顺序。
2、基于key的hash值存储,同样的对象hash值相同,所以元素不可重复,但是可以为null,可以快速查找是否包含某个元素。
LinkedHashSet
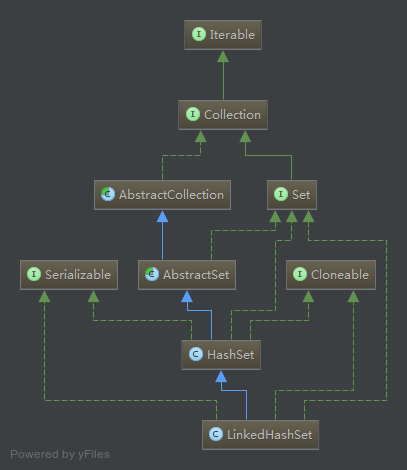
由类图我们可以看到,LinkedHashSet继承自HashSet,内部是基于LinkedHashMap来实现的。LinkedHashSet底层使用LinkedHashMap来保存所有元素,其所有的方法操作上又与HashSet相同,因此LinkedHashSet 的实现上非常简单,只提供了四个构造方法和一个spliterator方法,并通过传递一个标识参数,调用父类的构造方法,上文我们说到HashSet预留了一个不对外部公开的构造方法,就是用在这里。底层构造一个LinkedHashMap来实现,在相关操作上与父类HashSet的操作相同,直接调用父类HashSet的方法即可。
LinkedHashSet源码,由于底层使用LinkedHashMap作为存储结构,又继承了HashSet的各种方法,所以源码比较简单,这里就不做分析了,具体实现原理,参照Java集合框架之LinkedHashMap详解 一文。
特性总结
1、底层存储基于LinkedHashMap实现,内部使用双向链表存储元素,所以保证了元素的顺序性。
2、基于key的hash值存储,同样的对象hash值相同,所以元素不可重复,但是可以为null,可以快速查找是否包含某个元素。
TreeSet
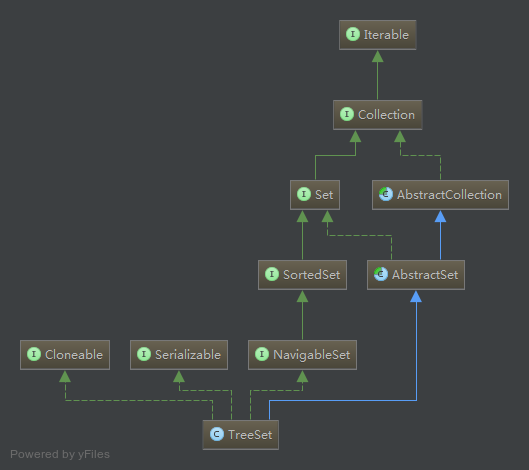
还是先看类图,TreeSet继承自AbstractSet,实现了NavigableSet接口,AbstractSet为抽象类,继承自AbstractCollection,实现了最基本的Collection骨架。TreeSet是基于TreeMap实现的有序集合,TreeSet中含有一个NavigableMap类型的成员变量m,而m实际上是TreeMap的实例。我们知道TreeMap内部是用红黑树实现元素存储从而保证元素的顺序性的,那么同理TreeSet同样也是一个有序的集合。通过源码我们知道TreeSet继承自AbstractSet,实现NavigableSet、Cloneable、Serializable接口。其中AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。NavigableSet是扩展的 SortedSet,具有了为给定搜索目标报告最接近匹配项的导航方法,这就意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。Cloneable支持克隆,Serializable支持序列化。由于TreeSet底层通过调用TreeMap实现,这里不再重复分析了,具体实现原理,参照Java集合框架之TreeMap详解 一文。
成员变量
构造方法
特性总结
1、底层存储基于TreeMap实现,内部使用红黑树结构表存储元素,所以保证了元素的顺序性。
2、元素不可为null。
2、遍历时不支持随机访问,只能通过迭代器和for-each遍进行遍历。
参考
http://www.jianshu.com/p/1f7a8dda341b
http://www.cnblogs.com/leesf456/p/5309809.html
http://blog.csdn.net/canot/article/details/51246944