本文基于jdk1.8介绍LinkedList。
在上一篇文章Java集合框架之ArrayList详解中, 我们介绍了Java集合框架下Collection接口的一个实现类ArrayList。通过源码分析,我们了解了ArrayList的存储结构和内部实现,今天我们再来看一下另外一个实现类LinkedList。
LinkedList
|
|
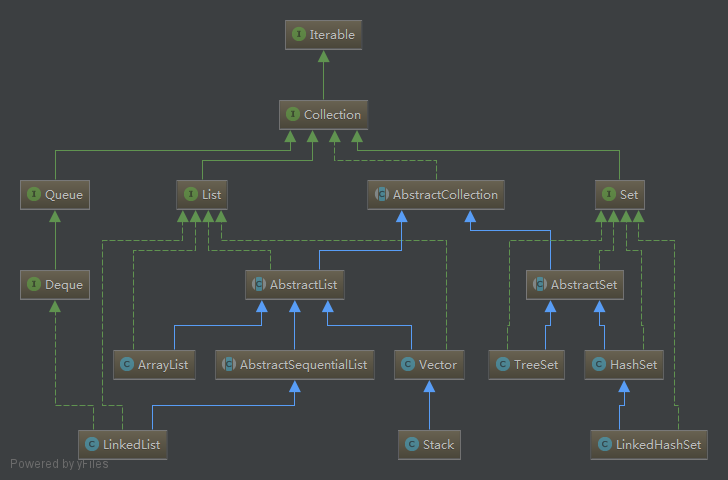
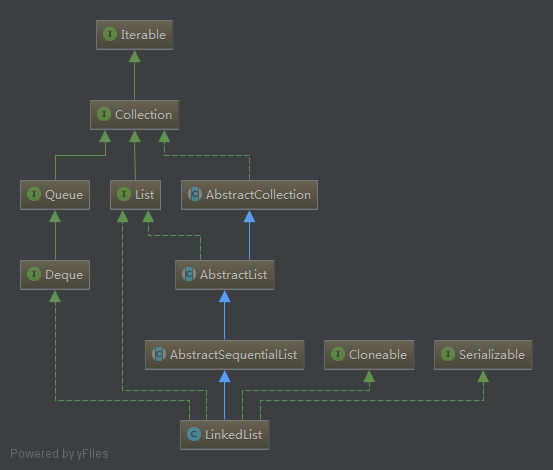
结合Collection和LinkedList的类图我们知道,LinkedList实现了List接口,并直接继承自AbstractSequentialList,AbstractSequentialList继承自AbstractList,AbstractSequentialList 把父类 AbstractList 中没有实现或者没有支持的操作都实现了,而且都是调用的 ListIterator 相关方法进行操作。还有一个就是继承了Deque接口,Deque接口表示是一个队列,那么也意味着LinkedList是双端队列的一种实现,所以,基于双端队列的操作在LinkedList中全部有效。
数据结构
我们还是先看一下LinkedList的数据结构,通过分析数据结构,看一下它的特性。通过查看源码,我们可以看到,在LinkedList的内部有一个内部类,其结构如下:
|
|

通过以上代码我们可以看到,在这个内部类Node中,有三个属性,item表示当前数据元素,next表示下一个元素的引用,prev表示前一个元素的引用。这很明显是一个双向链表的数据结构。LinkedList正是利用这个双向链表的数据结构实现了内部的元素存储,并通过维护一个头指针和尾指针,进行元素的增加和删除。基于这个数据结构,我们可以看到LinkedList的一些特性,比如有序性、元素可重复、可为空,上文我们还说到LinkedList继承了Deque接口,基于这样一个数据结构,我们可以将LinkedList当作一个双端队列来使用。
构造
下面我们看一下LinkedList的构造函数,LinkedList提供了两个构造函数,一个是默认的构造函数,实例化一个为空的LinkedList,另外一个可以传入一个Collection接口,将这个Collection转换为LinkedList。
存取
分析完数据结构和构造方法,我们重点来看一下LinkedList基于双向链表的存取的实现方式,我们结合源码先看一下添加的方法。LinkedList重写了add方法。
由代码我们可以看到,add函数用于向LinkedList中添加一个元素,并且添加到链表尾部,具体添加到尾部的逻辑是由LinkLast方法完成的。在LinkLast方法中,先构造一个新节点,并使last指向新节点。先用l备份last,再创建一个新的节点,并使last指向新节点。如果last为空,意味着原链表为空,需要把first指向新节点,否则使l的后继指向新节点,这样就完成了一次元素的插入。
获取元素
获取元素前会校验索引是否越界,没有越界的话就开始遍历链表,找到元素位置。这里并没有直接从链表的一端开始查找,而是利用了二分查找的思路,先判断给定的索引处在链表的什么位置,如果索引小于数组元素的一半,就从头指针开始查找,反之则从尾部开始查找,这里也体现了双向链表结构的优势,既可以向前查找,又可以向后查找。到这里我们明白,基于双向循环链表实现的LinkedList,通过索引Index的操作时是低效的,Index所对应的元素越靠近中间所费时间越长。而向链表两端插入和删除元素则是非常高效的(如果不是两端的话,都需要对链表进行遍历查找)。
遍历
对LinkedList遍历有以下几种方法:Iterator方式,for循环随机访问方式,foreach方式。对于这几种方式来说,效率最低下的是for循环随机访问的方式,为什么呢?因为在上一篇文章我们说到ArrayList实现了一个接口RandomAccess,此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。但是将操作随机访问列表的最佳算法(如 ArrayList)应用到连续访问列表(如 LinkedList)时,可产生二次项的行为。这是jDK API给出的解释,那通俗点讲是什么意思呢?我们知道LinkedList内部是使用双向链表实现的存储结构,一个链表节点除了存储元素本身外还存储了一个前驱几点的引用和后继节点的引用,注意这里存储的是引用,如果我需要查找第n个元素,不管是从链表头部开始查找还是从尾部开始查找,都需要先找到n-1或者n+1的元素,如果要找到n-1的数据那就要先找到n-1-1的数据,也就是说,需要把n之前或者之后的数据都访问一遍,才能访问到n。所以这样的方式是比较低效的,如果要遍历LinkedList,建议选择Iterator方式或者foreach方式。
总结
1、LinkedList基于双向链表结构实现存储,元素是有序的,并且元素可以为null、可以重复。
2、由于基于双向链表实现存储,增删比较快速,适用于频繁增删的场景。
3、查找比较耗时,遍历是需要注意,使用随机访问方式查找效率比较低下,需使用Iterator方式或者foreach方式遍历。
4、非线程安全,多线程环境慎用。
参考
http://www.jianshu.com/p/d5ec2ff72b33
http://www.blogjava.net/CarpenterLee/archive/2016/05/25/430333.html